[2024] [2023]
hey, I’m Ashok.
27.08.24
- lapack is an open source library for linear algebra operations on cpus.
- gpus have their own libraries for linear algebra operations such as cuBLAS for nvidia gpus, rocBLAS for amd gpus and mkl for intel gpus.
- lapack code is written in fortran.
26.08.24
- weight decay is used to prevent overfitting by penalizing weights over time in the loss function.
- the weight update equation becomes
where is the weight decay.
- some weights such as layer normalization weights are not decayed since overfitting is not a concern for them.
24.08.24
- for error
AttributeError: module 'numpy' has no attribute 'bool8'. Did you mean: 'bool', runpip3 install mxnet-mkl==1.6.0 numpy==1.23.1.
23.08.24
scpis helpful for copying files to the slurm scratch space.- example
scpcommand:scp -r a.py user@slurm_cluster_ip:/scratch/user/ - slurm clusters have multiple login nodes yet a single ip which leads to:
to resolve this, add
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@StrictHostKeyChecking noto~/.ssh/configorssh -o UserKnownHostsFile=/dev/null user@slurm_cluster_ip
21.08.24
- setting up ssh keys for github on linux machine:
then copy the key to github.
ssh-keygen -t rsa -b 4096 -C "email" eval "$(ssh-agent -s)" ssh-add ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub - website dependencies (Node >=
v20and npm >=v9.3.1):sudo apt install npm sudo npm install -g n sudo n latest node --version - website build command:
npx quartz build --serve.
03.08.24
Ctrl+Mswitches the theme between dark and light in wandb dashboard.
02.08.24
condacan be loaded on the Slurm cluster usingmodule avail condafrom the login node.- User directories should be created in
/scratch/<user_id>rather than on the login nodes, as login nodes are connected in a round-robin fashion, hence data may not persist across sessions. /scratch/folders are generally deleted after 3 weeks so routine backups are important.
29.07.24
- norm of a vector is defined as , it calculates the size of the vector depending upon the value of .
- norm is more commonly used and is also called the euclidean norm.
- Geometrically, in 2D space, forms a diamond shape whereas forms a circle.
- norm is sparse since it makes the coefficients zero whereas norm makes them small but non-zero.
26.07.24
- Currently, groq provides free inference to Llama models using API keys.
- model quantization reduces the precision of weights and biases to run the LLM models faster.d
- 8-bit and 4-bit quantization are commonly used for reducing the model size.
23.07.24
- send a new slurm job using:
sbatch job.shwherejob.shcontains the job commands. - view queued jobs using
squeue | grep gpuwhich will show the jobs using gpu nodes. - jobs have an upper time limit of 24 hours, so model checkpointing should be used to resume from a specific checkpoint for jobs that take longer.
20.07.24
- slurm clusters have two types of nodes: login node vs worker node.
- login nodes can access internet but worker nodes cannot.
- wandb requires access to
api.wandb.aibut since worker nodes do not provide that, an option is to store the data locally usingexport WANDB_MODE=offlineand then runwandb sync --sync-all --include-synced ./wandblater on from the login node which will sync the data.
17.07.24
- using wandb API key, multiple GPU nodes can send their logs to the central website.
- tmux commands for:
- detach:
<Ctrl-b> d - attach:
tmux a -t 0 - horizontal split:
<Ctrl-b> % - vertical split:
<Ctrl-b> "
- detach:
- for the error:
running,
libGL error: MESA-LOADER: failed to open swrast: /usr/lib/dri/swrast_dri.so: cannot open shared object file: No such file or directory (search paths /usr/lib/x86_64-linux-gnu/dri:\$${ORIGIN}/dri:/usr/lib/dri, suffix _dri) libGL error: failed to load driver: swrastfixes the issue.cd /home/$USER/anaconda3/envs/$ENV/lib mkdir backup mv libstd* backup cp /usr/lib/x86_64-linux-gnu/libstdc++.so.6 ./ ln -s libstdc++.so.6 libstdc++.so ln -s libstdc++.so.6 libstdc++.so.6.0.19
16.07.24
- unknown traceback:
Traceback (most recent call last): File "run.py", line 333, in <module> run_experiment(parser.parse_args()) File "run.py", line 115, in run_experiment agent.train() File "/home/cse/Desktop/ashok/agents/model.py", line 352, in train norm = torch.nn.utils.clip_grad_norm_( File "/home/cse/.local/lib/python3.8/site-packages/torch/nn/utils/clip_grad.py", line 20, in _no_grad_wrapper return func(*args, **kwargs) File "/home/cse/.local/lib/python3.8/site-packages/torch/nn/utils/clip_grad.py", line 76, in clip_grad_norm_ raise RuntimeError( RuntimeError: The total norm of order 2.0 for gradients from `parameters` is non-finite, so it cannot be clipped. To disable this error and scale the gradients by the non-finite norm anyway, set `error_if_nonfinite=False` - gradient clipping is used to avoid exploding gradient problem.
- yet, if the gradients are
InforNaNthen it returns the above traceback. Overflow in numbers due to insufficient data type can also cause this.
06.07.24
- import gym versions:
0.18forfrom gym.env.classic_control import rendering as visualize.0.21for change in rendering frompyglettopygame.
05.07.24
AttributeError: module 'wandb.proto.wandb_internal_pb2' has no attribute 'Result'can be resolved by:pip install protobuf==3.20 pip install wandb==0.16.6AttributeError: partially initialized module 'charset_normalizer' has no attribute 'md__mypyc' (most likely due to a circular import)can be resolved by:pip install --force-reinstall charset-normalizer==3.1.0
04.07.24
- setting up
sshon a new machine:sudo apt install openssh-server sudo systemctl start ssh sudo systemctl enable ssh
01.07.24
gym > 0.26.0replacesdonewithterminatedandtruncated.terminatedindicates that the episode ended due to a terminal state, whereastruncatedindicates that the episode ended due to a time limit.
29.06.24
isortto sort imports in python files, alphebetically.pylintto check for code quality.
28.06.24
torchvision.datasets.ImageFoldercan be used to load images from a folder when the folder structure is:root/dog/xxx.png root/dog/xxy.png root/cat/123.png root/cat/456.png
25.06.24
wandb synccan be used to upload the training directory from local to cloud.
24.06.24
- for error:
'extras_require' must be a dictionary whose values are strings or lists of strings containing valid project/version requirement specifiers, run:pip install setuptools==65.5.0 pip==21 pip install wheel==0.38.0 wandb login --relogin --cloudfor logging through online account.
22.06.24
- to clone a specific branch,
git clone --single-branch --branch <branch_name> <repo_url>. - for AnyDesk error
Failed to load module "canberra-gtk-module", installlibcanberra-gtk-moduleusingsudo apt-get install libcanberra-gtk-module libcanberra-gtk3-module. - nvidia_gpu_exporter
(:9835)exports the metrics on/metricswhich is scraped by prometheus(:9090)and visualized by grafana(:3000). - grafana
(:3000)installation commands:sudo apt-get install -y adduser libfontconfig1 musl wget https://dl.grafana.com/oss/release/grafana_11.0.0_amd64.deb sudo dpkg -i grafana_11.0.0_amd64.deb - nvidia_gpu_exporter
(:9835)installation commands:sudo dpkg -i nvidia-gpu-exporter_1.1.0_linux_amd64.deb - prometheus
(:9090)installation commands:then edit thewget https://github.com/prometheus/prometheus/releases/download/v2.45.6/prometheus-2.45.6.linux-amd64.tar.gz tar -xvf prometheus-2.45.6.linux-amd64.tar.gz sudo groupadd --system prometheus sudo useradd -s /sbin/nologin --system -g prometheus prometheus sudo mkdir /etc/prometheus sudo mkdir /var/lib/prometheus cd prometheus-2.45.6.linux-amd64 sudo mv prometheus /usr/local/bin sudo mv promtool /usr/local/bin sudo mv console* /etc/prometheus sudo mv prometheus.yml /etc/prometheus sudo chown prometheus:prometheus /usr/local/bin/prometheus sudo chown prometheus:prometheus /usr/local/bin/promtool sudo chown prometheus:prometheus /etc/prometheus sudo chown -R prometheus:prometheus /etc/prometheus/consoles sudo chown -R prometheus:prometheus /etc/prometheus/console_libraries sudo chown -R prometheus:prometheus /var/lib/prometheussudo nano /etc/prometheus/prometheus.ymlfile to:next, runglobal: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'node' static_configs: - targets: ['localhost:9100'] # Adjust the target to your node exporter endpoint - job_name: 'nvidia_exporter' static_configs: - targets: ['localhost:9835'] # Adjust the target to your node exporter endpointsudo nano /etc/systemd/system/prometheus.serviceand add the following to it:lastly,[Unit] Description=Prometheus Wants=network-online.target After=network-online.target [Service] User=prometheus Group=prometheus Type=simple ExecStart=/usr/local/bin/prometheus \ --config.file /etc/prometheus/prometheus.yml \ --storage.tsdb.path /var/lib/prometheus/ \ --web.console.templates=/etc/prometheus/consoles \ --web.console.libraries=/etc/prometheus/console_libraries [Install] WantedBy=multi-user.targetsudo systemctl daemon-reload sudo systemctl enable prometheus sudo systemctl start prometheus sudo systemctl status prometheus
21.06.24
torch.bmmis used for batch matrix multiplication. It expects the input tensors to be of shape(batch, n, m)and(batch, m, p)and returns a tensor of shape(batch, n, p).torch.nn._scaled_dot_product_attentionis used in transformers for scaled dot product attention. Torch code for (64, 10, 128), (64, 12, 128) and (64, 12, 128):def torch.nn._scaled_dot_product_attention(Q, K, V): attn_weights = torch.bmm(Q, K.transpose(1, 2)) / (128 ** 0.5) attn = torch.bmm(F.softmax(attn_weights, dim=-1), V)- attn_weights = (64, 10, 128) x (64, 128, 12) = (64, 10, 12)
- attn = attn_weights(64, 10, 12) x (64, 12, 128) = (64, 10, 128)
- .shape = attn.shape = (64, 10, 128), .shape = .shape = (64, 12, 128).
20.06.24
- if the error on boot is
bad shim signature, you need to load the kernel first, disableSecure Bootin BIOS and try again. - boot error:
ata7: COMRESET failed (errno=-32)is merely a warning and the system does boot up.
19.06.24
- setting up a dual node gpu cluster from scratch is a daunting task.
18.06.24
- grafana can be used for visualizing data from prometheus. Usally, prometheus has a node exporter that collects system metrics and sends them to prometheus. Grafana can then be used to visualize these metrics.
- node_exporter for nvidia gpu can be found here.
17.06.24
- to preserve code changes to a folder on the gpu server, I archive the folder contents excluding the
wandbfolder using:#!/bin/bash # Check if the archive name is provided as an argument if [ -z "$1" ]; then echo "Usage: $0 archive_name.tar" exit 1 fi # Archive name from the first argument ARCHIVE_NAME="$1" # Exclude the wandb folder and create the tar archive tar --exclude='./wandb' -cvf "$ARCHIVE_NAME" ./ echo "Archive created: $ARCHIVE_NAME"
16.06.24
- manually installing
.debfiles:sudo dpkg -i <filename>.deb.
15.06.24
-
When running jupyter notebook, if you get the error
ImportError: cannot import name 'contextfilter' from 'jinja2' (/home/user/anaconda3/lib/python3.8/site-packages/jinja2/__init__.py), switch tobaseconda environment and runpip install jinja2==3.0.3 nbconvert==6.4.4. -
Error:
Missing optional dependency 'pytables'. Use pip or conda to install pytables.can be resolved by runningpip install tables. -
To convert
csvof format:Time,Sensor1,Sensor2,Sensor3 00:00,10,15,5 01:00,12,18,8 02:00,14,20,7to
csvof format:timestep location value 0 00:00 Sensor1 10 1 01:00 Sensor1 12 2 02:00 Sensor1 14use,
long_format_data = data.melt(id_vars=['Time'], var_name='location', value_name='value') long_format_data.rename(columns={'Time': 'timestep'}, inplace=True)
13.06.24
- google provides the Secure Shell extension for ssh in chrome.
- accessing gpu through docker requires installation of
nvidia-container-toolkitusing:followed by:curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listfollowed by:sudo apt-get update sudo apt-get install -y nvidia-container-toolkit nvidia-docker2 sudo systemctl restart dockersudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker nvidia-ctk runtime configure --runtime=docker --config=$HOME/.config/docker/daemon.json systemctl --user restart docker
12.06.24
- Double Deep Q Network (DDQN) 1 uses two networks to decouple the target and estimation networks .
- the target network is updated less frequently than the estimation network . This approach helps in stabilizing the training of the q-network.
- equation for DDQN:
05.06.24
- a higher learning rate and a lower learning rate, both can cause the model to diverge.
- a higher learning rate can cause the model to overshoot the minima.
- a lower learning rate can cause the model to get stuck in a local minima.
01.06.24
richpython library can be used for rich text and beautiful formatting in the terminal.
28.05.24
- SARSA is an on-policy algorithm, whereas Q-learning is an off-policy algorithm.
- Equation for SARSA:
- Equation for Q-learning:
- Off-policy algorithms require a replay buffer to store the transitions.
24.05.24
-
If you get this error:
hp@admin ~/D/D/RPS [1]> pip install --upgrade pip (py312) Traceback (most recent call last): File "/home/hp/miniconda3/envs/py312/bin/pip", line 5, in <module> from pip._internal.cli.main import main File "/home/hp/miniconda3/envs/py312/lib/python3.12/site-packages/pip/_internal/cli/main.py", line 8, in <module> from pip._internal.cli.autocompletion import autocomplete File "/home/hp/miniconda3/envs/py312/lib/python3.12/site-packages/pip/_internal/cli/autocompletion.py", line 9, in <module> from pip._internal.cli.main_parser import create_main_parser File "/home/hp/miniconda3/envs/py312/lib/python3.12/site-packages/pip/_internal/cli/main_parser.py", line 7, in <module> from pip._internal.cli import cmdoptions File "/home/hp/miniconda3/envs/py312/lib/python3.12/site-packages/pip/_internal/cli/cmdoptions.py", line 22, in <module> from pip._internal.cli.progress_bars import BAR_TYPES File "/home/hp/miniconda3/envs/py312/lib/python3.12/site-packages/pip/_internal/cli/progress_bars.py", line 9, in <module> from pip._internal.utils.logging import get_indentation File "/home/hp/miniconda3/envs/py312/lib/python3.12/site-packages/pip/_internal/utils/logging.py", line 14, in <module> from pip._internal.utils.misc import ensure_dir File "/home/hp/miniconda3/envs/py312/lib/python3.12/site-packages/pip/_internal/utils/misc.py", line 20, in <module> from pip._vendor import pkg_resources File "/home/hp/miniconda3/envs/py312/lib/python3.12/site-packages/pip/_vendor/pkg_resources/__init__.py", line 58, in <module> from pip._vendor.six.moves import urllib, map, filter ModuleNotFoundError: No module named 'pip._vendor.six.moves'then run
curl -sS https://bootstrap.pypa.io/get-pip.py | python3to reinstall pip. -
sudo pacman -Syu xfce4 xfce4-goodiesto install xfce4 desktop environment on arch linux. -
to auto start xfce4 on boot, add:
if [ -z "$DISPLAY" ] && [ "$XDG_VTNR" = 1 ]; then exec startxfce4 fito
~/.bash_profile.
23.05.24
- arch install script inside live arch iso:
archinstall - almost all linux distros require internet connection
- use iwctl to connect to wifi before running
archinstallusing:iwctl station list station wlan0 get-networks station wlan0 connect <SSID> exit ping google.com
22.05.24
-
rnn hidden state equation:
where,
- is the hidden state at time ,
- is the input at time ,
- is the input-to-hidden weight matrix,
- is the input-to-hidden bias,
- is the hidden-to-hidden weight matrix,
- is the hidden-to-hidden bias.
-
architecture of a simple rnn:

-
how can agents remember the past in reinforcement learning?
20.05.24
- if
conda activatereturns an error:
usage: conda [-h] [-v] [--no-plugins] [-V] COMMAND ...
conda: error: argument COMMAND: invalid choice: 'activate' (choose from 'clean', 'compare', 'config', 'create', 'info', 'init', 'install', 'list', 'notices', 'package', 'remove', 'uninstall', 'rename', 'run', 'search', 'update', 'upgrade', 'build', 'content-trust', 'convert', 'debug', 'develop', 'doctor', 'index', 'inspect', 'metapackage', 'render', 'skeleton', 'env', 'verify', 'server', 'pack', 'token', 'repo')then run source ~/anaconda3/etc/profile.d/conda.sh to export conda functions.
03.05.24
- linear quadratic regulator (LQR) for optimal control.
02.05.24
- model quantization for fpga
01.05.24
- fpga mindmap:
%%{init: {'theme': 'default', 'themeVariables': { 'fontSize': '18px', 'fontFamily': 'Montserrat'}}}%% mindmap root((fpga)) $$$ logic gates nand nor language verilog vhdl boards xilinx altera digilent pynq Z2 DE10 linux lxde tang nano 9k machine learning model quantization hls4ml CNN mnist dataset live testing using camera Transformers
29.04.24
-
types of low-level chips: microcontroller, fpga
-
microcontroller mindmap:
%%{init: {'theme': 'default', 'themeVariables': { 'fontSize': '20px', 'fontFamily': 'Montserrat'}}}%% mindmap root((microcontroller)) $ 8-bit arduino uno r3 atmega328p SMD (surface mount device) DIP (dual in-line package) easier to solder (through hole) 16MHz crystal bare-metal atmega328p breadboard crystal - 16MHz capacitors resistors switch, leds 32-bit stm32 esp32 rpi pico Language C Rust CircuitPython and Micropython Tools avrdude -
TinyMaix for inference of MNIST on atmega328p.
26.04.24
- in partially observable markov decision process (POMDP), observation state.
- mermaid.js for creating diagrams such as mindmaps in markdown.
uno r3input voltage is 7-12V, output voltage is 5V.
25.04.24
\ldotsis for low dots in latex whereas\cdotsis for center dots.\hrulefillin latex creates a horizontal line that fills the width of the page.
24.04.24
-
strikethrough text in latex using:
\usepackage{soul} \st{Strike through this text} -
mac doesn’t support multiple hdmi to usb-c adapter. Only one hdmi can be connected at a time.
22.04.24
sshport forwarding:ssh -L 8080:localhost:8080 user@remotehostforwards the remote port8080to the local port8080.
20.04.24
- sparse rewards lead to unstable training, whereas dense rewards lead to faster convergence.
- sparse rewards are more realistic but harder to learn.
- reward shaping through imitation learning can help in learning sparse rewards.
19.04.24
- jumanji
connector-v2environment does not guarantee solvability. - get the version of ubuntu using
lsb_release -a. - installing
nleusing pip can be a chore since the error messages are not helpful. steps to install on ubuntu22.04:sudo apt-get install -y build-essential autoconf libtool \ pkg-config python3-dev python3-pip python3-numpy git \ flex bison libbz2-dev wget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | sudo apt-key add - sudo apt-add-repository 'deb https://apt.kitware.com/ubuntu/ jammy main' sudo apt-get update && apt-get --allow-unauthenticated install -y \ cmake \ kitware-archive-keyring conda create -n py38 python=3.8 conda activate py38 pip install nle
18.04.24
xlais a compiler for machine learning models. It performs better on GPU and TPU.jaxusesxlaas a backend and has syntax similar tonumpy.mavais a marl library that usesjaxas a backend.
17.04.24
- in sb3,
batch_sizecan be changed forDQNandPPO. - what’s the right batch size to use?
16.04.24
-
sbxnow supports custom activation functions. resolved with PR#41. Now, it works withTD3,PPO,SAC,DDPGandDQN. -
policy specifies .
-
In on-policy, behaviour policy estimation policy, whereas, in off-policy, behaviour policy estimation policy.
PPOis on-policy andDQNis off-policy. -
Generally, on-policy is used for fast environments and off-policy is used for slow environments.
-
tmux:
- prefix key:
Ctrl-bby default. - New window:
<prefix>c - Next window:
<prefix>n - Previous window:
<prefix>p.
- prefix key:
-
tui file manager:
nnn.
15.04.24
-
sumo charging station on the road using:
<additional> <chargingStation chargeDelay="2" chargeInTransit="0" power="200000" efficiency="0.95" startPos="10" endPos="25" id="cS_2to19_0a" lane="2to19_0"/> </additional> -
dynamic time warping (DTW) (Berndt & Clifford 1994) is used to check the similarity between two time series.
-
change target vehicle color to red:
traci.vehicle.setColor(vehID, (255, 0, 0))
14.04.24
-
to get the color of the plotted line in matplotlib:
p = plt.plot(x,x, x,x*2, x,x*3) colors = [line.get_color() for line in p] -
default
plt.figsizeis (6.4, 4.8) inches.
13.04.24
-
multi-armed bandit is a simpler version of reinforcement learning, regret equation:
where,
- is the cumulative regret,
- is the number of time steps,
- is the optimal reward at each time step,
- is the reward at time step .
-
can multi-armed bandit perform better than reinforcement learning in some cases?
12.04.24
- spatio-temporal dataset:
pems08. ctrl-tabin vscode to switch between open files.- policy gradient is on-policy whereas q-learning is off-policy.
- equation for policy gradient:
which uses stochastic gradient ascent.
06.04.24
- pure param embeddings are randomly initialized and learned during training. they are not tied to any input token.
- cross attention with a pure param embedding is getting common.
05.04.24
pwnagotchiruns on rpi zero w and uses a wifi adapter to capture handshakes.- it uses rl to learn the best way to capture handshakes.
- what’s the bill-of-materials for a pwnagotchi?
04.04.24
- neovim distributions exist such as
lazyvimandspacevim. - they come with pre-installed plugins and configurations.
- lazygit is a terminal based git client with cool UI.
- lazydocker is a terminal based docker client with cool UI.
03.04.24
- rpi pico w has two cores.
- code for printing even numbers on
core0and odd numbers oncore1:
from time import sleep
import _thread
def core0_thread():
counter = 0
while True:
print(counter)
counter += 2
sleep(1)
def core1_thread():
counter = 1
while True:
print(counter)
counter += 2
sleep(1)
second_thread = _thread.start_new_thread(core1_thread, ())
core0_thread()02.04.24
- if importing both
torchandtensorflowin the same script, and you get an error:
F ./tensorflow/core/kernels/random_op_gpu.h:246] Non-OK-status: GpuLaunchKernel(FillPhiloxRandomKernelLaunch<Distribution>, num_blocks, block_size, 0, d.stream(), key, counter, gen, data, size, dist) status: Internal: invalid configuration argumentthen import tensorflow before torch.
sbxdoesn’t support custom activation functions yet. work in progress. link to github issue.
01.04.24
- tensorboard logs only 1000 steps by default to preserve memory but this results in exported csv files lacking data.
- To increase the number of steps in tensorboard logs, use
--samples_per_plugin=scalars=10000in thetensorboardcommand. - rgb smd led model:
KY-009. Working voltage: 2.8 for red, 3.2 for green, 3.2 for blue. Forward current: 20mA.
29.03.24
- setting up a new rpi pico w with micropython requires downloading the micropython firmware.
thonnyis the preferred editor. It is available in standard ubuntu repo.- if you get an error
Unable to connect to /dev/ttyACM0: [Errno 13] could not open port /dev/ttyACM0: [Errno 13] Permission denied: '/dev/ttyACM0'try,sudo usermod -a -G dialout <username>and then logout or reboot. thonnyin the ubuntu repos is kinda outdated and doesn’t have native support for pico w. download the latest using:
wget -O thonny-latest.sh https://thonny.org/installer-for-linux
chmod +x thonny-latest.sh
./thonny-latest.sh-
in
thonny, go to Run -> Interpreter -> Micropython (Raspberry Pi Pico) -> install or update micropython. -
hold the
BOOTSELbutton and then plug the micro-usb to get the mcu into filesystem mode. -
pico wcode for blinking on-board led is different frompicobecause its connected to a gpio on the wireless chip instead. -
code for blinking on-board led on
pico w:
import machine
led = machine.Pin("LED", machine.Pin.OUT)
led.off()
led.on()-
save the file as
main.pyon the pico w filesystem to make it run on boot. -
images:
- rpi pico gpio pins
- rpi pico in its packaging
- rpi pico alongside arduino for size comparison
- rpi pico led blink




28.03.24
- overleaf docker container: github link.
- texstudio also works well,
sudo apt install texstudio.
27.03.24
- trajectory stitching involves piecing together parts of the different trajectories.
- it helps offline rl match the performance of online rl.
- sub-optimal algorithms can be stitched to perform better than them.
26.03.24
- in latex,
\include{}adds a new page, instead use\input{}. - embedded firmware just means the arduino code.
24.03.24
- rpi pico supports micropython and its only 6$. ¯\_(ツ)_/¯
- its also dual core so it can multi-task.
simplapackage in SUMO does not work withlibsumo.
23.03.24
STM32F103RBhas 128KB flash and 72MHz clock speed. It was about 14$.- micropython requires a minimum of 256KB flash.
- micro:bit v2 has 512KB flash, 128KB RAM, and 64MHz clock speed. It has nRF52 chip.
- micro:bit can be programmed using micropython.
- python access index using enumerate:
for index, element in enumerate(['a', 'b', 'c']):
print(index, element)22.03.24
- db9 is a serial port connector. db15 is a vga connector. T_T
21.03.24
- pdf on how to use rplidar on windows to scan the environment.
20.03.24
- nvim config is stored at
~/.config/nvim/init.vim. - minimal vim/nvim config:
syntax on
set tabstop=4
set shiftwidth=4
set expandtab
set autoindent
set number
set ruler- for error:
AttributeError: module 'tensorflow_probability' has no attribute 'substrates'useimport tensorflow_probability.substrates.jax as tfp. - Parse local TensorBoard data into pandas DataFrame
19.03.24
-
MAE loss is less sensitive to outliers.
-
MSE loss penalises large errors.
-
MAE is not differentiable whereas huber loss is better because its differentiable.
-
images:
- mae vs mse vs huber
- huber at different values of can become MSE or MAE.
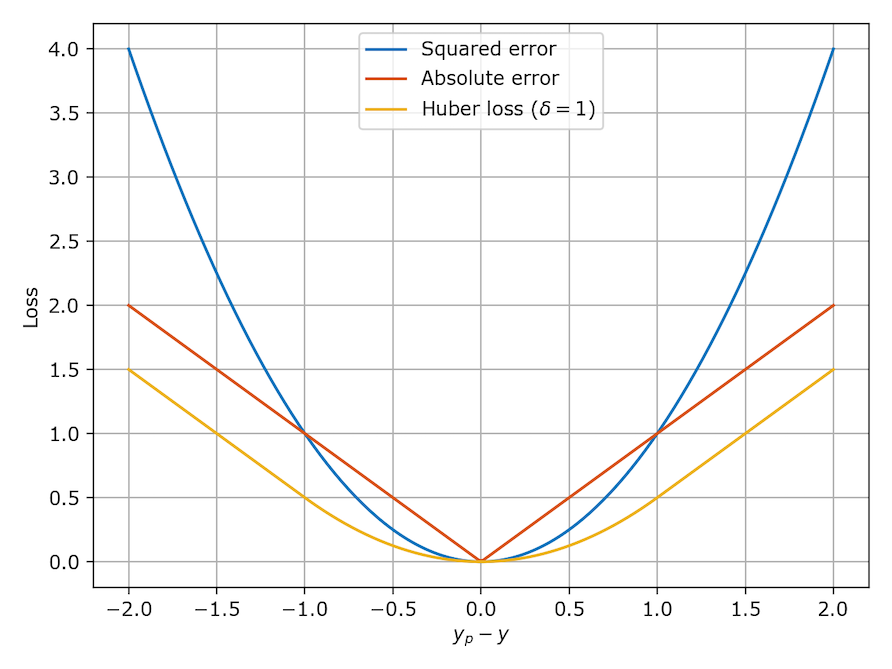
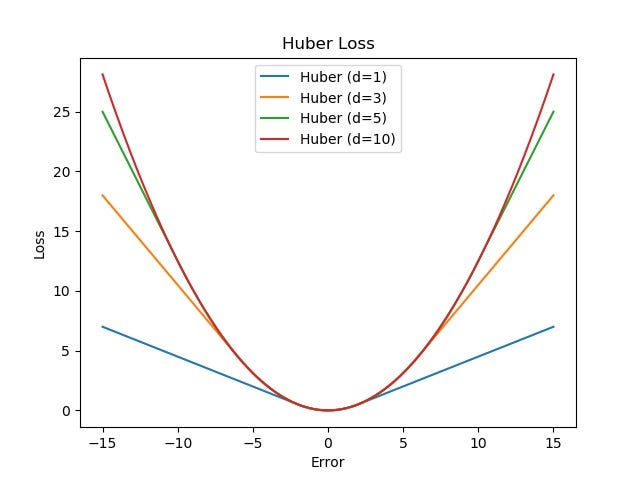
-
-
in vim, switch between splits: Ctrl-W + [hjkl].
-
and reload the current file using
:e. -
ai inference hardware is getting better. tenstorrent sells e150 for 75k inr (shipping included).
-
quantization reduces the size of the model and makes it less memory hungry.
18.03.24
- rpi pins max output is 3.3v.
- how to monitor the rpi temperature?
- is gpio cleanup necessary?
16.03.24
- gpio pin layout is actually this way:

-
5v to 3.3v converter: HW-122 (AMS1117-3.3).
-
the converter can be used for rpi to arduino serial communication.
15.03.24
- ring attention is useful for increasing the context size.
miniforgeworks better on raspberry pi.- pinout.xyz for pin layout.
13.03.24
- UART is a serial communication protocol.
- Enabling serial on RPi 4:
sudo raspi-configInterfacing Options>Serial>No>Yes- Reboot
- GPIO connections:
TXof RPi toRXof USB to TTLRXof RPi toTXof USB to TTLGNDof RPi toGNDof USB to TTL
minicomcan be used to access the serial console of RPi. (sudo apt install minicom)minicom -b 115200 -o -D /dev/ttyUSB0to start minicom with baud rate 115200 and device/dev/ttyUSB0- disable hardware flow control in minicom using
Ctrl+A>O>Serial port setup>F>No
12.03.24
- the notes belong to different categories, can I use a LLM to classify them without any labels? Each bullet point is a note and the category is the label.
- the categories could be:
-
Embedded
-
ML
-
GPU/Infra
-
Programming
-
Latex
-
Unlabelled
-
11.03.24
- to reduce matplotlib xticks:
num_xticks = 5 # Number of x-ticks to show
step = len(time_steps) // num_xticks
plt.xticks(time_steps[::step], rotation=45, fontsize=15) # Set x-axis ticks to show only selected time steps-
usb-c power delivery (pd) can deliver variable voltage and current using software negotiation.
-
power delivery trigger board can be used to negotiate power delivery and get a fixed voltage and current.
-
\usepackage{graphicx}and\usepackage{subcaption}for subfigures in latex.
10.03.24
- how to flash a blank
stm32f030f4p6chip? - blinking led is the hello world of embedded systems
- today’s commit deletes the old format files.
nvidia-driver-350is compatible withcuda-11.8.nvidia-driver-250is compatible withcuda-11.5.- to switch display driver from
nvidiatointel, usenvidia-prime:
sudo apt install nvidia-prime
sudo prime-select intel- install cuda 11.8:
wget https://developer.download.nvidia.com/compute/cuda/repos/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.runand update path using:
$ export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}
$ export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64\
{LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}- when building cuda libraries using ninja if you get an error:
/usr/include/c++/11/bits/std_function.h:435:145: error: parameter packs not expanded with ‘...’:
435 | function(_Functor&& __f)
| ^
/usr/include/c++/11/bits/std_function.h:435:145: note: ‘_ArgTypes’
/usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
530 | operator=(_Functor&& __f)
| ^
/usr/include/c++/11/bits/std_function.h:530:146: note: ‘_ArgTypes’then install gcc-10 and g++-10:
sudo apt install gcc-10 g++-10
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-10 10
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-10 10and update version:
Ubuntu 22.04.1 LTS
Cuda compilation tools, release 11.8, V11.8.89
gcc (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
g++ (Ubuntu 9.5.0-1ubuntu1~22.04) 11.3.0-
bash_aliasesis a file to store aliases for bash commands such asexport PATHandexport LD_LIBRARY_PATH. -
To install pytorch with cuda support:
conda install pytorch=*=*cuda* cudatoolkit -c pytorch09.03.24
- there’s no desktop ARM processors.
- a usb to ttl converter
pl2303hxcan be used to access the serial console of a raspberry pi. - ssh gives virtual console whereas serial console gives physical console.
- serial console doesn’t require wifi or hdmi.
armis alsorisc.
08.03.24
- embedded languages: c, c++, rust
- rust can run bare metal on raspberry pi using
no_stdandno_maincrate-level attributes - bare metal can be used to run code without an operating system
07.03.24
- lora is duplex by default. It can send and receive at the same time.
- analog pins on arduino can be used as digital pins too.
- arduino D0 and D1 pins although set aside for TX and RX can also be used as digital pins.
05.03.24
- nvidia display driver is different from nvidia cuda driver.
- cuda version in
nvidia-smiis not the installed version. nvcc --versiongives the installed cuda version.
04.03.24
- neo6m gps module connects to the satellite and gives the location in NMEA format.
- it has a cold start time of 27s and a hot start time of 1s. on my desk, it took 2-5 minutes to get a fix.
- once fixed, it saves it to the eeprom and can be retrieved on the next boot.
- the eepron battery is a coin cell.
03.03.24
einsumis cool. It uses the Einstein summation convention to perform matrix operation.torch.einsum('ij,jk->ik', a, b)is equivalent totorch.matmul(a, b)- its drawbacks are that its not optimized on gpu (yet). Also doesn’t allow brackets in the expression.
>>> a = torch.rand(3, 5)
>>> a
tensor([[0.7912, 0.6213, 0.6479, 0.2060, 0.9857],
[0.9950, 0.7826, 0.6850, 0.6712, 0.0524],
[0.4367, 0.8872, 0.9622, 0.0159, 0.4960]])
>>> b = torch.rand(5, 3)
>>> b
tensor([[0.4560, 0.9680, 0.1179],
[0.9072, 0.8982, 0.2926],
[0.5526, 0.2779, 0.5810],
[0.4366, 0.8061, 0.0065],
[0.4744, 0.6915, 0.5326]])
>>> torch.einsum('ij,jk -> ik', a,b)
tensor([[1.8401, 2.3517, 1.1779],
[1.8601, 2.4338, 0.7766],
[1.7780, 1.8429, 1.1344]])
>>> torch.matmul(a, b)
tensor([[1.8401, 2.3517, 1.1779],
[1.8601, 2.4338, 0.7766],
[1.7780, 1.8429, 1.1344]])stm32f030f4p6as per the naming convention means:stm32is the family of microcontrollersfis the series = General purpose0is the core count = ARM Cortex-M030is the line numberfis the pin count = 204is the flash size = 16KBpis the package type = TSSOP6is the temperature range = -40 to 85 degree celsius
02.03.24
- The
stm32f030f4p6chip is SMD and in TSSOP-20 footprint. - I also bought SMD to THT adapters which are called
breakout boardsand soldered the chip to it. - STM32 nucleo boards come with a built-in st-link programmer and debugger.
images:
stm32f030f4p6soldered onto a breakout boardstm32f030f4p6with rpi v4 for scale


01.03.24
- v100s has 5120 cuda cores and 640 tensor cores
- quadro rtx 5000 has 3072 cuda cores and 384 tensor cores
- tensor cores are more important for deep learning than cuda cores
- installing miniconda:
# install miniconda
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
source ~/.bashrc- installing nvidia gpu drivers:
# install nvidia drivers
sudo apt update && sudo apt upgrade
sudo apt autoremove nvidia* --purge
ubuntu-drivers devices
sudo apt install nvidia-driver-525
sudo reboot
nvidia-smi
# install pytorch with cuda support
pip install torch torchvision torchaudio- ICs come in different packages: DIP, SOP, QFP, TQFP
29.02.24
- softmax suffers from numerical instability due to floating point precision error
>>> import torch
>>> m = torch.nn.Softmax(dim=1)
>>> a = torch.tensor([[ 0.4981e3, 0.5018, -0.7310]])
>>> m(a)
tensor([[1., 0., 0.]])- normalization is a way to solve numerical instability
>>> torch.nn.functional.normalize(a)
tensor([[ 1.0000, 0.0010, -0.0015]])
>>> m(torch.nn.functional.normalize(a))
tensor([[0.5762, 0.2122, 0.2117]])28.02.24
- color sensors (TCS34725, TCS3200) can detect intensity of R,G,B individually
- because of open source, risc v is cheaper than arm and runs linux too
- microcontroller (arduino, stm32) vs single board computer (raspberry pi, beaglebone)
- models perform better when data is gaussian
27.02.24
warmup_stephyperparameter lowers the learning rate for the first few steps and then increases it- transformer = encoder + decoder + attention
Kis the context window size in the attention mechanism which is the number of tokens that each token attends to.- attention in transformers has quadratic time complexity
- flash attention has linear time complexity
- An Attention Free Transformer also has linear time complexity
wandbcan be self-hosted too inside the docker container
26.02.24
- cpu architectures: x86, x86_64, arm, arm64, risc-v
- famous arm dev board: stm32
- risc-v is open source and is gaining popularity
- LuckFox Pico Plus RV1103 is a risc-v dev board with ethernet and can run linux
- softmax not summing to 1 T_T
- how to make LoRa full duplex?
25.02.24
- rl implementations: stable-baselines3
- cleanrl has single file implementations of rl algorithms
- tianshou is a pytorch based rl library
- Through Hole Technology (THT) vs Surface Mount Technology (SMT)
24.02.24
- Found this Machine Learning Theory Notes GDrive